目次
概要
結局Bulldozerってどうなの
Bulldozer アーキテクチャ
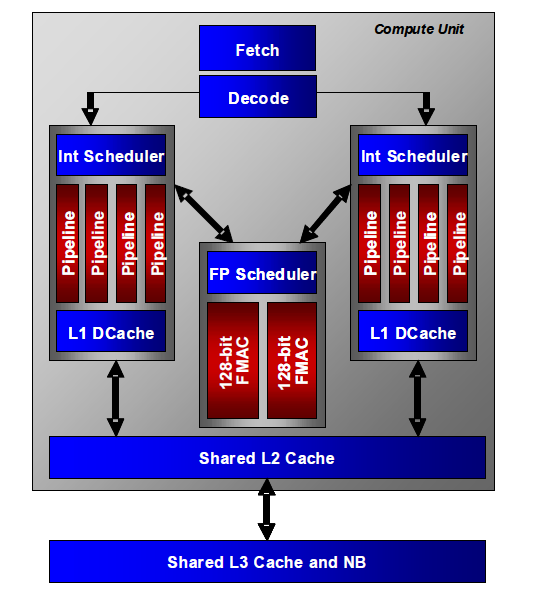
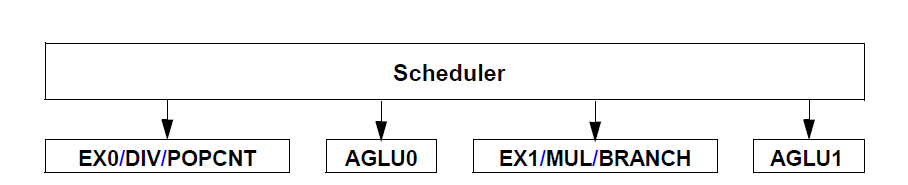
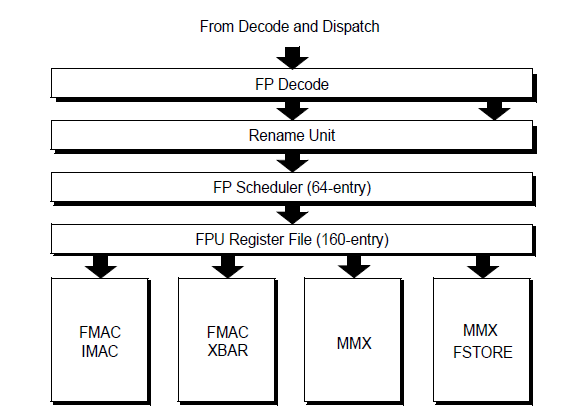
Software Optimization Guide for AMD Family 15h Processorsより
- ふたつのコアで1モジュールを構成する
- それぞれのコアは、4本の整数パイプと、L1D を持つ
- 整数は、基本的な演算+メモリアクセスを実行するAGLUx2 と、パイプごとに対応する命令を実行するEXx2の4本
- L1I、Fetch、Decode、L2、FPUはふたつのコアで共有されている
- L1I->Fetchは32Byte、4命令デコード/clk
- FPUは、4本が色々と命令できて、うち2本が128bit FMAを実行できる
思想としては、
- FPUはリソース多く使うので無駄遣いしないように実行効率を上げたい → FPUをヘヴィに使うプログラムでは HT みたいになる
- 整数は軽いのでたくさん入れたい → サーバー等ではHTよりも絶対性能高い
ということなんだと思われる。
命令単位ベンチマーク
実際どうなっているか命令単位でベンチマークしてみる
手元(A8-4500M)で動かした時の結果(なんかTurbo Boost止められなかったので実際には1.9GHzのrdtscクロックが2.3GHzのCPUクロックにあうように値調整してます)
$ bench-ipc <ループ回数> <Thread1 affinity> <Thread2 affinity> ... とかやって使う
$ bench-ipc 1000000 0 2 3 # 100万回ループして、スレッド0をコア0に、スレッド1をコア2に、スレッド2をコア3に割り当てる ipc4 0:00000001:2.074932 1:00000010:2.051553 2:00000100:1.090766 ^ ^ ^ | | | | | 命令を実行するのにかかったクロック | | | アフィニティマスク | スレッドID
これでスレッド割り当てと IPC の関係を見る
ipc4
ADD は EX、MOVのロードは AGLU なので、これをあわせれば IPC 4 出る
add ecx, 1
add edx, 1
mov esi, mem[0]
mov edi, mem[0]
========================================
$ ./rdtsc.exe 100000 0 1 2
ipc4
0:00000001:2.074932
1:00000010:2.051553
2:00000100:1.090766
Core 0,1 は、同じモジュール、 Core2は別モジュールになっていて、 Core 0,1 では、4命令あたり 2clk、 Core 2は、4命令あたり 1clkで実行できる。
add4x
sse の整数演算は、FPUで実行されるので、シングルスレッドなら整数演算を4命令/clkで実行できる。これは(多分)x86史上最強のALUを積んでるということである。
add ecx ,1
add edx ,1
paddd xmm0, xmm0
paddd xmm1, xmm1
add ecx, 1
add edx, 1
paddd xmm2,xmm2
paddd xmm3,xmm3 # paddd はレイテンシ2あるので埋めるために8命令実行する
========================================
add4x
add4x
0:00000001:4.070786
1:00000010:4.070721
2:00000100:2.067680
Core 2 では、8命令あたり 2clk で実行できる。
add2_mem
L1D は、コアで占有されていて、2read できるので、2スレッドで4read できるはず…!と見せかけてできない…!
add ecx, mem
add edx, mem
========================================
add2_mem
0:00000001:2.004254
1:00000010:2.001533
2:00000100:1.108393
なんで? Agner さんの microarchitecture.pdf にもなんか出ないとか書いてあって
No explanation has been found for this reduced throughput.
Agnerさんをもってしてもよくわからない現象っぽい。
fadd2
1コアでFPU占有すれば、浮動小数演算は 2op/clk 出る
xorps xmm0, xmm0
addss xmm0, xmm0
xorps xmm0, xmm0
addss xmm0, xmm0
========================================
fadd2
0:00000001:2.069074
1:00000010:2.063987
2:00000100:1.038717
シングルスレッドならmul x 2 も可能である。これは(多分)x86史上最強のFPUを積んでいるということである。
store_forwarding, store_forwarding2
Bulldozer 出るか出ないかの頃は 2ch でよく L2 write-through() とか書いてあったが実際どうなのか。
実際には、Storeした直後の値は、StoreBufferに入っていて、それを読めばStore-Forwardingされるから、実害は控えられるはず…
なら、store forwardingミスったらどうなるの?というのが 2
# store_forwarding
mov [mem], ecx
mov ecx, [mem]
# store_forwarding2 (32bit のうち下位8bitに書き込んだ直後に32bit読む)
mov [edi+4], cl
mov ecx, [edi+1]
========================================
store_forwarding
0:00000001:8.582095
1:00000010:8.133118
2:00000100:8.219721
store_forwarding2
0:00000001:34.957176
1:00000010:34.570470
2:00000100:30.401867
結構大きい…が、いきなりメモリレイテンシ分止まるというわけではないみたい。(どういう実装なんだろうか?)
まとめ
シングルスレッド性能だけを見ると
- Fetch32Byteは、Sandy/K10と並んで史上最高タイ
- ピークIPC=4は、CoreMAと並んで史上最高タイ
- デコード性能は4/6でCoreMAより劣る
- x86史上最強の整数ALU
- x86史上最強のFPU
→ 史上最強のx86の誕生か!?
(シャッフルみたいにスループット下がってる命令もあるので若干誇張があります)
ほんまかよ…?
himenoBMT
FPUをヘヴィに使って、簡単なベンチマークということで、himenoBMTを動かしてみる
cl(64bit ver 16.00) で /O2 /Zi /DSSMALL でビルド
結果
- A8-4500M(2.3GHz) -> MFLOPS measured : 1430
- i7-3400(3.4GHz) -> MFLOPS measured : 3604
…史上最強とはなんだったのか…
クロック比を考えても、約1.7倍の性能差が存在しているようにしか見えない。
フェッチ22byte?
Agnerさんによると、シングルスレッドだと命令フェッチが MAX 22byte しか出ないとか書いてある。 命令フェッチの帯域の計測方法よく知らないので実測してないが、 64bitのhimenoBMTだと、 グローバルに変数置かれてる都合上、命令が、 REX + SSE のプレフィクスx2 + opcode + modrm + sib + disp32 で、 9byteになっているものがある。 これだと、Max 22byteのフェッチ幅だと、2命令/clkしかissueできない…
(と、勉強会で説明したのですが、その時の指摘にもあったように、Nehalem/Core2が16byteフェッチでそれよりは大きいので、特別これが弱いとするのはちょっとおかしいかもしれないです)
マルチスレッドだと
himenoBMTをふたつ起動して、processexplorerでaffinity設定して、 A8 ではモジュールに乗るように、i7ではコアに乗るようにした。結果(スレッドあたり)↓
- A8: 1150 MFLOPS
- ivy : 1800 MFLOPS
(ivyはシングルスレッドの丁度半分でシングルスレッドから完全に依存見つけてるんだろうかすごい)
クロック比を考慮すると、差は6%まで縮んでいる。
つまり、依存関係が無い命令を発行できれば、カタログ値に見合った性能を発揮している。
→ なんか依存関係を見つけられてないのでは。
RS(Reservation Station) の深さ
似たような問題をK10 vs CoreMAの時にも見た(http://int.main.jp/txt/k10/#sec6。つまり、RSの深さがIvyよりも足りないのではないかという説。
最適化マニュアルには、FPUはRSの深さ60とか書いてあって、Sandyよりもリッチなのだが、 K10と同じく合計60で、実際には4本の各パイプごとに深さ15づつぐらいしか無いのだろうと予想される。
前と同じ方法で測った。つまり、命令の依存を長くしていって、どのぐらいでレイテンシ見えてくるか測った。
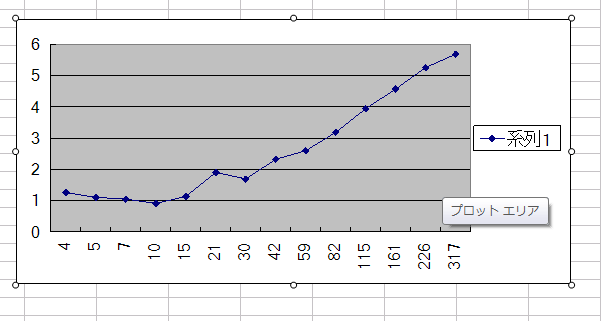
mulss
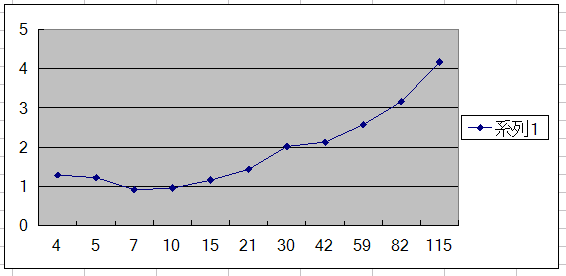
addss
横軸が命令の依存の長さ。縦軸が命令あたりの平均クロック数。レイテンシを隠蔽できれば理論スループット(addss,mulssともに1)に近付くはず
どう見ても60もあるように見えない。15x4 だと考えたほうが妥当だと思われる。
深さ15は、K10の14よりも増えているが、浮動小数やSSE命令のいくつかは地味にレイテンシ増えてるので、 強化されていると言えるかは微妙ではないか
himenoBMTからわかること- やっぱり K10と同じく RSの深さが足りない
- 64bitでは 22byte issue はきつい
Dhrystone
整数もやっておくか。
(Dhrystoneはちょろっとした関数を呼ぶだけなので、現代のアーキテクチャのベンチマークとしては向かないと思いそうだが、むしろ昨今のプログラムは小さいBBが並んでるみたいなのが多いので、むしろ現代のソフトウェアにあっているのではないかという説)
印象を書くなら、
- シングルスレッドで同じくらい
- マルチスレッドで2倍!!
結果
- A8 : Dhrystones per Second: 11500000
- i7 : Dhrystones per Second : 22800000
…しじょうさいきょうのx86さん… (クロック比を考慮しても30%ぐらい)
マルチスレッドで動かすと↓
- A8 : Dhrystones per Second: 8500000
- i7 : Dhrystones per Second : 12550000
クロック比考慮するとちょうど同じくらい
まとめ
- カタログスペックはi7 1コアとBull 1Moduleで同じくらい。
- ただし依存関係検出がK10と比べてほとんど進化してないので、1Moduleの性能を出すには 2スレッド作る必要がある
というように見える。
参考文献
Software Optimization Guide for AMD Family 15h Processors : 公式
The microarchitecture of Intel, AMD and VIA CPUs: An optimization guide for assembly programmers and compiler makers : 上で "Agner さんの"とか書いてるやつ
この文書について
この文書はx86/x64最適化勉強会4のために書かれました。