目次
概要
経緯 : http://d.hatena.ne.jp/w_o/20141021#1413893835
Host 1700msec、Epiphany 170msecとかになって、さすが、16coreだから10倍速いみたいな話になったが、 経験的に、こういうのってナイーブCと比較してるから、普通にマルチスレッド & NEON使えば、10倍差ぐらいすぐはやくなんじゃね? と、思ってNEON + スレッド化matmulを探したのだけど、見当たらなくて、探すより書いたほうがはやそうだったので書いた。
というのがあって、今更matmulを実装したのでその話について書く。
- 1ノード
- Haswell
- 正方行列
- 単精度
- サイズは128の倍数だとか制限付けてもよい
という条件でどうやって効率上げていくかについて説明する。
今日の結果は N = 2000〜3000 で効率 80% ぐらい。
まあ多分もっと詳しい dgemm Ninja は世界にたくさんいる気がするけど、x86 の FMA ありでちゃんと文章になっている説明は見付からなかったので、そういうのは気にしない。
いまどきのmatmulというタイトルだが、1ノードの話しかしてないし、Haswellはもう一世代昔になってしまったのであまりいまどきではない。
動作環境
特に記載が無いものは、
- Intel(R) Core(TM) i7-4700MQ CPU @ 2.40GHz (4C8T)
- Linux 3.16.0
- gcc 4.9.1
- echo never > /sys/kernel/mm/transpalrent_hugepage/enabled # huge page なし
- echo 2500000 | tee /sys/devices/system/cpu/cpu*/cpufreq/scaling_{min,max}_freq # なんかよくわからんけど2500000指定すると2.4GHzになる
- 何回か実行して、目視で一番良さそうな値を採用
で計測
matmul
行列積(Matrix Multiply)のこと。
// C = A x B (Ver1)
for (i=0; i<N; i++) {
for (j=0; j<N; j++) {
for (k=0; k<N; k++) {
C[i][j] += A[i][k] * B[k][j];
}
}
}
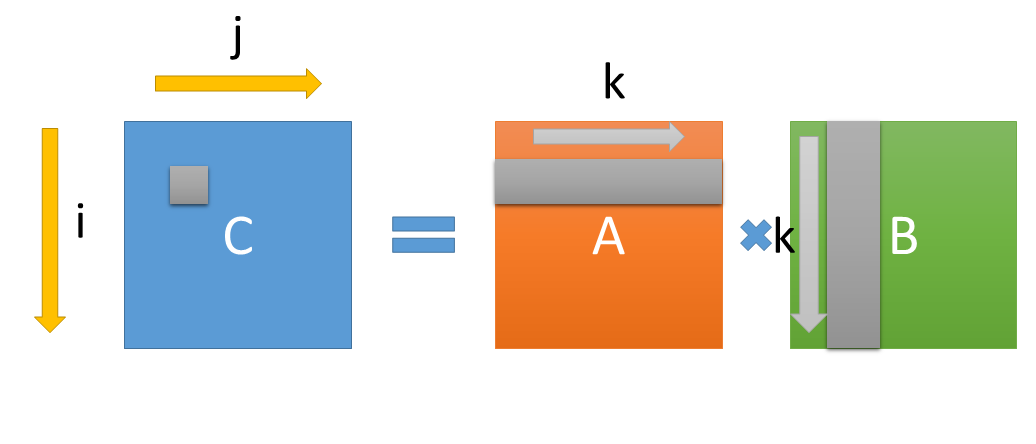
TOP500 で使う HPLinpack の性能を決めるのがこれ(らしい。よく知らない。あと dgemm はスカラ値α、βを使うので完全に同じではない)。
正方行列で、サイズが NxN だとすると、計算量のオーダーが O(N^3) になる。N^2 のデータに対して、 N^3 の演算があるので、メモリが相対的に遅い、最近のコンピュータでも性能を出しやすい。計算量を減らすアルゴリズムもあるが、LINPACKレギュレーションでは使ってはいけないらしい(とWikipediaに書いてあった)
5分でわかる matmul 最適化
一度でも matmul 書いたことある人は知ってると思うが、一番の問題は、
C[i][j] += A[i][k] * B[k][j] ;
の B[k][j] 部分で、これが、(C言語 のように Row Majorなら) 縦方向のアクセスになる。
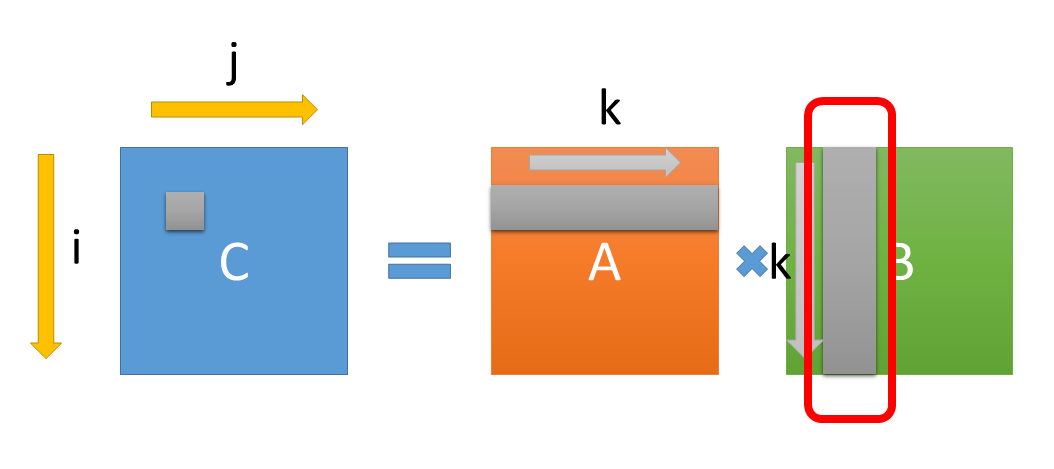
縦方向のアクセスには、以下のような問題がある。
- キャッシュラインはx86なら64byteだが、ロードした64byteのうち一要素(単精度なら4byte)しか使わない
- MMUのページがアクセスごとに変わるので TLB ミスが発生しやすい
- ハードウェアプリフェッチが働かない
- SIMD にならない
matmul は、sumとってる以外は依存の無いコードなので、(Cが0初期化されてるなら)i,j,k のループ順序は、任意に並びかえてよい。
// Ver2
for (j=0; j<N; j++) {
for (k=0; k<N; k++) {
for (i=0; i<N; i++) {
C[i][j] += A[i][k] * B[k][j];
}
}
}
これでも良い。
配列の添字は、C[i][j], A[i][k], B[k][j] と、なっており、 j のループは、A,B,C 全て、Row が変化しないことがわかる。つまり、最内ループにjを持ってくると、最内ループでRowが変わらないプログラムに変形できる。
// Ver3
for (i=0; i<N; i++) {
for (k=0; k<N; k++) {
for (j=0; j<N; j++) {
C[i][j] += A[i][k] * B[k][j];
}
}
}
N = 1024 の場合、Ver1: 0.66[GFLOPS], Ver3: 2.7[GFLOPS] となって、ループ順序を入れかえるだけで4倍速くなる
Nが8の倍数なら、FMA 化はすぐできる。更新されるのが、C[i][j] なので、i もしくは j で依存無く並列化できる。
// Ver4
// 変数名変わってるけど気にしないで。 out=C, inL = A, inR = B です
for (unsigned long i=i_start; i<i_end; i++) {
for (int k=0; k<n; k++) {
__m256 lik = _mm256_broadcast_ss(&inL[i*n+k]);
for (int j=0; j<n; j+=8) {
__m256 o = _mm256_loadu_ps(&out[i*n+j]);
__m256 r = _mm256_loadu_ps(&inR[k*n + j]);
o = _mm256_fmadd_ps(lik, r, o);
_mm256_storeu_ps(&out[i*n+j], o);
}
}
}
これで Ver4 : 54.6[GFLOPS] となる。
| ver | Ver1 | Ver3 | Ver4 |
| GFLOPS | 0.66 | 2.7 | 54.6 |
まとめ
ループ入れかえてSIMD + マルチスレッドにしたら90倍も速くなったので良かった。(完)
そんなわけはない
実際Haswellってどのぐらい性能出るの?
最初に書いたとおり、matmul は非常に性能を出しやすい処理なので、matmul の性能を見るときは、ピーク性能だけではなくて、理論性能に対して何割ぐらいの性能が出ているかも見ることが多い。
matmul は、ほぼ積和、ロード、ストアに律速するので、これだけ見ればよい。
Intel(R) 64 and IA-32 architectures optimization reference manual の、 Figure 2-1. や http://agner.org/optimize/ の Instruction Tables を見ると、次のようになっている。
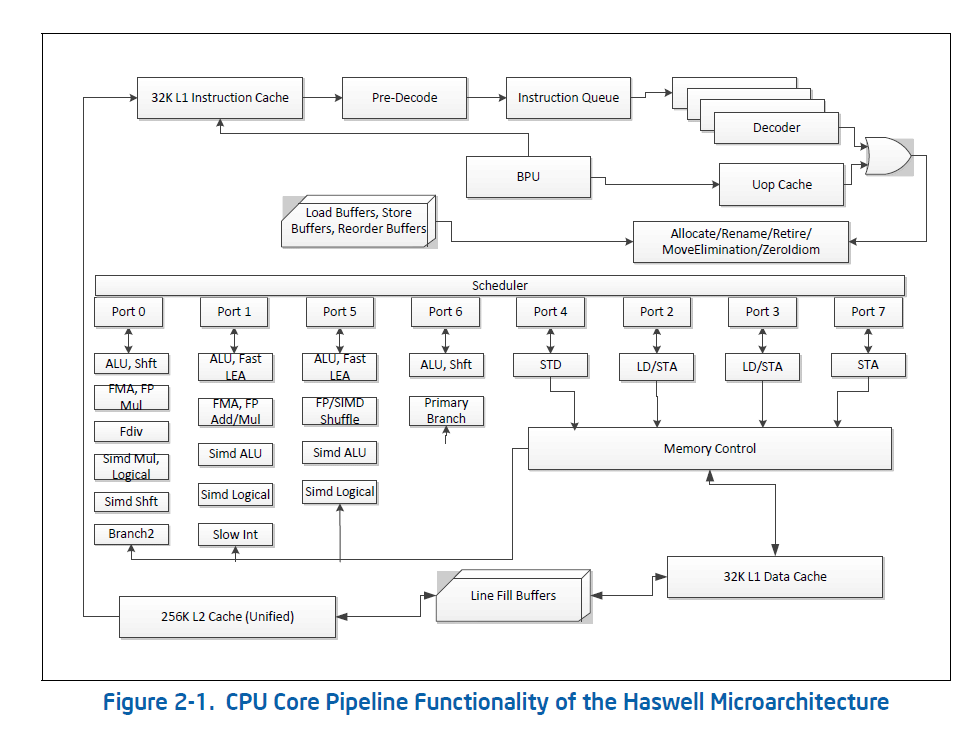
Intel(R) 64 and IA-32 Architectures Optimization Reference Manual の Figure 2-1
| 種類 | ポート | スループット |
| FMA | Port0, Port1 | 2 |
| Load, Prefetch | Port2, Port3 | 2 |
| Store | Port4 | 1 |
単精度なら、FMA一回で、8個の積和ができるので、これで16FLOP。これがポート2個あるので、サイクル当たり32FLOP。今使っているi7 2.4GHz 4Coreなら、32 x 2.4 x 4 = 307.2 [GFLOPS] が理論ピークとなる。
FMA 演算一個に対して、ロードが1個、ストアが0.5個ぐらいの比率にする必要がある。さらに、デコードが4命令という制約もあるので、FMA、ロード、ストアあわせてクロックあたり4命令以下にする必要がある。
実際には、ループ制御、プリフェッチ等、他の処理も必要なので FMA 2個に対して、ロードとストアあわせて1個未満の比率ぐらいにしたい。
FMA化 + マルチスレッド化した Ver3 でも、まだ 54.6 / 307.2 = 17.8[%] しか性能出てなくて、フル性能出せるならこっから5倍くらい速くなるはず。
| ver | Ver1 | Ver3 | Ver4 |
| GFLOPS | 0.66 | 2.7 | 54.6 |
| 理論性能比[%] | 0.2 | 0.8 | 17.8 |
100GFLOPS を目指して
Ver4 は、最内ループが
for (int j=0; j<n; j+=8) {
__m256 o = _mm256_loadu_ps(&out[i*n+j]);
__m256 r = _mm256_loadu_ps(&inR[k*n + j]);
o = _mm256_fmadd_ps(lik, r, o);
_mm256_storeu_ps(&out[i*n+j], o);
}
こうなっているが、これは、ロードx2, ストアx1, FMAx1 となっており、ロードストアで律速している。
Ver1 は、C[i][j] のロードストアが外に出せるので、
for (i=0; i<N; i++) {
for (j=0; j<N; j++) {
float Cij = 0;
for (k=0; k<N; k++) {
Cij += A[i][k] * B[k][j];
}
C[i][j] = Cij;
}
}
ロードx2, FMAx1 となるので、Ver3,Ver4 は、演算数だけ見るとVer1 より悪い。 C は、更新される値なので、最内ループでi,jを変化させてしまうと、ストアの回数が増えてしまうのである。 命令数を減らすには、最内ループでは、Ver3,Ver4のやりかたは良くなくて、C をレジスタに乗せる必要がある。
レジスタブロッキング
最初に説明したように、matmul は、行列サイズがNxN なら、ロード:演算比は、1:N になる。今は最内ループで ロードx2、FMAx1 となっているが、工夫すれば、もっと演算の割合を増やすことができるはず。これをやるのをレジスタブロッキングと呼ぶ。
matmul は、i,j,kのループの順番を好きなように入れかえられる。これは、i,j,k,i,j みたいなループもできるということである。例えば、
// Ver5
for (i0=0; i0<N; i0+=2) {
for (j0=0; j0<N; j0+=2) {
float Cij[2][2] = {0};
for (k=0; k<N; k++) {
for (i1=0; i1<2; i1++) {
for (j1=0; j1<2; j1++) {
Cij[i1][j1] += A[i0+i1][k] * B[k][j0+j1];
}
}
}
C[i+0][j+0] = Cij[0][0];
C[i+0][j+1] = Cij[0][1];
C[i+1][j+0] = Cij[1][0];
C[i+1][j+1] = Cij[1][1];
}
}
みたいに、外のi,jは、一個とばしでループを回して、kの内側で、i,j を二回ずつ回す、というようにできる。
このVer5のi1,j1のループは定数なので、デメリットほぼ無しにアンロールできるアンロールすると、
// Ver6
for (i0=0; i0<N; i0+=2) {
for (j0=0; j0<N; j0+=2) {
float Cij[2][2] = {0};
for (k=0; k<N; k++) {
Cij[0][0] += A[i0+0][k] * B[k][j0+0];
Cij[0][1] += A[i0+0][k] * B[k][j0+1];
Cij[1][0] += A[i0+1][k] * B[k][j0+0];
Cij[1][1] += A[i0+1][k] * B[k][j0+1];
}
C[i+0][j+0] = Cij[0][0];
C[i+0][j+1] = Cij[0][1];
C[i+1][j+0] = Cij[1][0];
C[i+1][j+1] = Cij[1][1];
}
}
こうなって、これを少し最適化すると、(このぐらいはコンパイラがやってくれるが)
// Ver7
for (i0=0; i0<N; i0+=2) {
for (j0=0; j0<N; j0+=2) {
float Cij[2][2] = {0};
for (k=0; k<N; k++) {
float A0k = A[i0+0][k];
float A1k = A[i0+1][k];
float Bk0 = B[k][j0+0];
float Bk1 = B[k][j0+1];
Cij[0][0] += A0k * Bk0;
Cij[0][1] += A0k * Bk1;
Cij[1][0] += A1k * Bk0;
Cij[1][1] += A1k * Bk1;
}
C[i+0][j+0] = Cij[0][0];
C[i+0][j+1] = Cij[0][1];
C[i+1][j+0] = Cij[1][0];
C[i+1][j+1] = Cij[1][1];
}
}
こうなる。Ver1 では、FMA:ロード比が、 1:2 だったが、Ver7 は、FMA:ロード比が4:4 になっており、良くなっていることがわかる。
これはどういうことかというと、Ver1 は、
こういう処理だったが、この、C[i][j] を求める時に必要な、A[i][0..N] は、C[i][j+1] を求める時にも使われる。
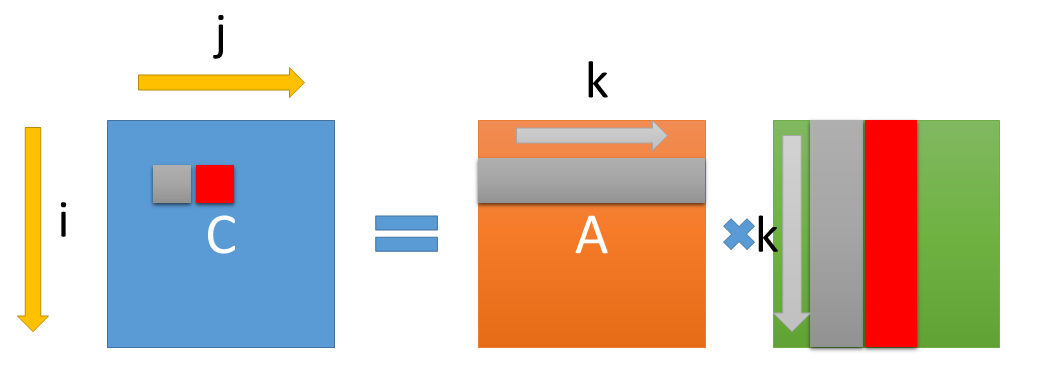
これを考えると、C[i][j] と、 C[i][j+1] を同時に計算すれば、A[i][0..N] のロード回数を一回減らせるというわけである。
B についても同様に、C[i][j] と、 C[i+1][j] を同時に計算すれば、B[0..N][j] のデータを再利用できる。
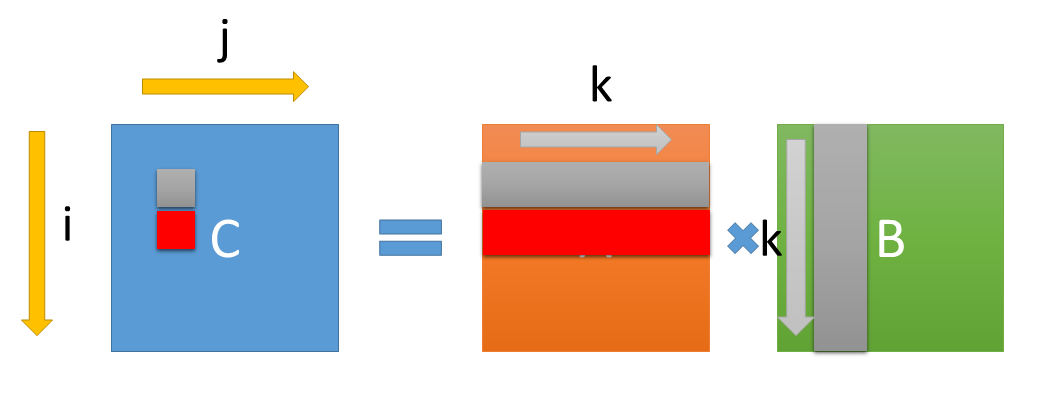
C[i][j], C[i][j+1], C[i+1][j], C[i+1][j+1], を同時に計算すると、A2回ロード、B2回ロードの計4回ロードで4回のFMAが実行できる。これで FMA : ロード比は 1:1 になる。
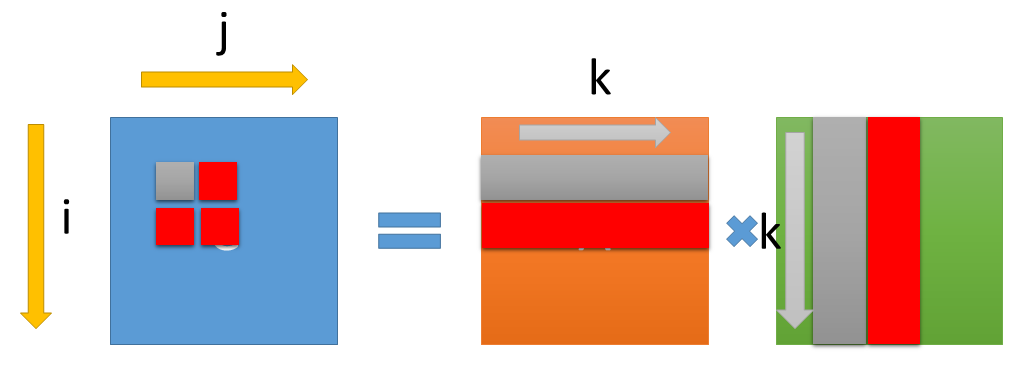
さて、では、このブロッキングはどのぐらいの数にすればよいかだが、ブロックサイズが大きいほど、FMA:ロード比を大きくできるが、ワーキングセットが大きくなって使用するレジスタ数が増えるというトレードオフがあるので、レジスタ数で制限される。
あと、Haswell の FMA レイテンシは、5で、スーパースカラ2並列なので、並列に実行するFMA数は、最低でも10必要になる。
この条件を考えると、ブロックサイズは 4x3 あたりが良さそうという感じになる。4x3なら、
- Cij を 4x3 の 12 個用意する
- A or B のブロック小さいほう(3個) をロードする (これでレジスタ15個使う)
- A or B のブロック大きいほうを一個ロードする。FMAを3回する。これを4回くりかえす
となって、
- 使用レジスタ16個
- 並列FMA数 12個
- FMA : ロード比 12:7
となる。(FMA を使わない場合は途中の値を保持する必要があるので、一時レジスタがもう一個必要)
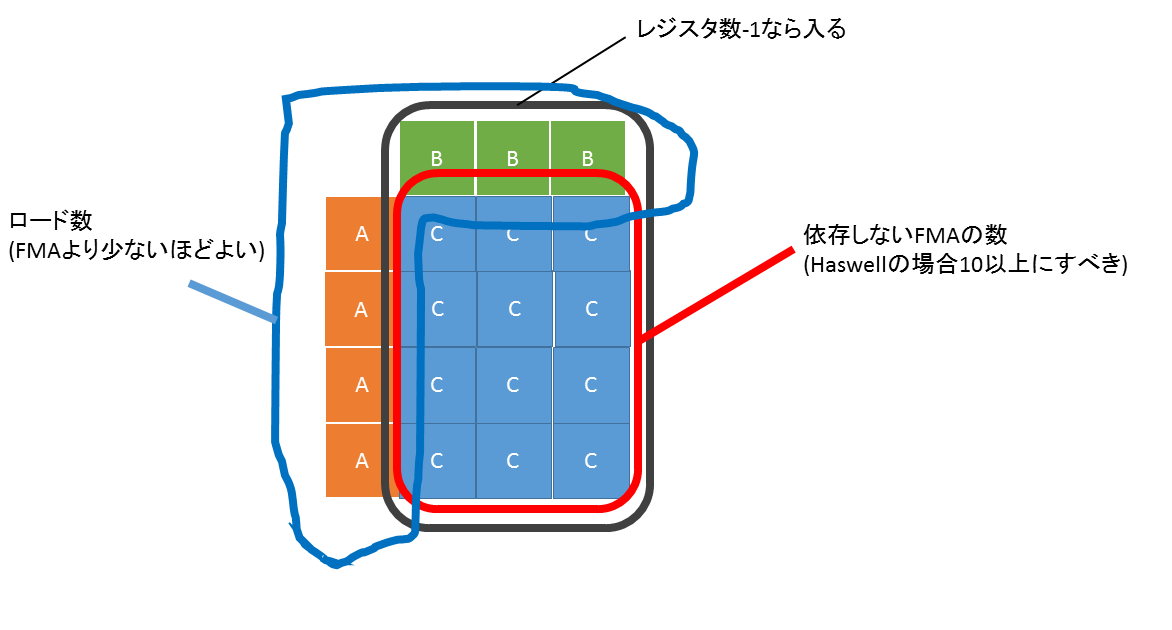
このバージョンは試して 4x2 が速かったので4x2にしている。理由は…よくわからん。
以上を実装したプログラムが、
// Ver8
#define AVX_K8(K) \
{ \
const float *inL00 = inL0; \
\
_mm_prefetch((const char*)(inR0 + pitch_f32*4), _MM_HINT_T0); \
\
lik0_8 = _mm256_set1_ps(*inL00); \
inL00+=pitch_f32; \
vr0 = _mm256_load_ps(&inR0[0]); \
\
AVX_OP(0,0); \
lik1_8 = _mm256_set1_ps(*inL00); \
inL00+=pitch_f32; \
AVX_OP(1,0); \
LOAD_LIK2_8(); \
AVX_OP_2(0); \
\
vr1 = _mm256_load_ps(&inR0[8]); \
AVX_OP(0,1); \
AVX_OP(1,1); \
AVX_OP_2(1); \
\
vr2 = _mm256_load_ps(&inR0[16]); \
AVX_OP(0,2); \
AVX_OP(1,2); \
AVX_OP_2(2); \
\
vr3 = _mm256_load_ps(&inR0[24]); \
AVX_OP(0,3); \
AVX_OP(1,3); \
AVX_OP_2(3); \
inL0++; \
inR0 += pitch_f32; \
}
こういう大変読みやすいリーダブルコードになった。
全体見たい場合は https://github.com/tanakamura/matmul-bench/blob/0315/matmul-bench-avxfunc.h#L12 各自見ておいて。
これであとアンロールしたりプリフェッチしたり細かいチューンして、N = 2048 のときに、122[GFLOPS] ぐらい。
| ver | Ver1 | Ver3 | Ver4 | Ver8 |
| GFLOPS | 0.66 | 2.7 | 54.6 | 122.6 |
| 理論性能比[%] | 0.2 | 0.8 | 17.8 | 39.9 |
DTLB ミス削減
でもまだ40%ぐらいだった。問題は TLB ミスである。
http://www.7-cpu.com/cpu/Haswell.html
Haswell の L1D は 8way 32KB、キャッシュライン64byteとすると、64 line x 8 way となる。一方 L1 DTLB は全wayで64 entryとなっており、アクセスごとにページが変わると、L1D ミスよりも、L1 DTLB ミスの問題のほうが先に表面化する。単精度matmulの場合は、N = 1024 を超えると、行ごとに別ページになるので、B は、DTLB ミスにひっかかってしまう。
さらに、L1D ミスは、演算量が十分多ければ、プリフェッチで隠蔽できる が、DTLB は、プリフェッチが無い。(プリフェッチ命令は、L1 DTLB 当たらないと、何もしなくなる)。つまり…つまりどうしたらいいんだ…
転置するというアイデアがある。転置は最初に一回すればよく、O(N^2)でできるので、N が十分大きければ無視できるはず…だが、メモリ使用量のレギュレーション的に転置していいのかどうかわからないので、まあちょっと使う分だけ転置してみる。
// Ver9
for (j=0; j<N; j++) {
for (i=0; i<N; i++) { // B と関係無いiを内側に入れる
for (k=0; k<N; k++) {
if (i==0) {
B_t[k] = B[k][j]; // i=0 で B[0..N][j] を B_t[0..N] へコピー
}
C[i][j] += A[i][k] * B_t[k]; // B_t[0..N] を使う
}
}
}
i が変わらないようにして、B の再利用率を上げる。i=0 で B[j][k] を B_t[k] へコピー。
コードは https://github.com/tanakamura/matmul-bench/blob/6x2/matmul-bench-fma.c#L191 こうなる。(Ver10)
// Ver10
for (l_hi=0; l_hi<n; l_hi++) {
r0 = _mm256_loadu_ps(Rline + 0);
r1 = _mm256_loadu_ps(Rline + 8);
Rline += 8*2; // ここが連続アドレスになっている
l0 = _mm256_broadcast_ss(pl0);
o00 = _mm256_fmadd_ps(l0, r0, o00);
o01 = _mm256_fmadd_ps(l0, r1, o01);
l1 = _mm256_broadcast_ss(pl1);
o10 = _mm256_fmadd_ps(l1, r0, o10);
o11 = _mm256_fmadd_ps(l1, r1, o11);
l2 = _mm256_broadcast_ss(pl2);
o20 = _mm256_fmadd_ps(l2, r0, o20);
o21 = _mm256_fmadd_ps(l2, r1, o21);
l3 = _mm256_broadcast_ss(pl3);
o30 = _mm256_fmadd_ps(l3, r0, o30);
o31 = _mm256_fmadd_ps(l3, r1, o31);
l4 = _mm256_broadcast_ss(pl4);
o40 = _mm256_fmadd_ps(l4, r0, o40);
o41 = _mm256_fmadd_ps(l4, r1, o41);
l5 = _mm256_broadcast_ss(pl5);
o50 = _mm256_fmadd_ps(l5, r0, o50);
o51 = _mm256_fmadd_ps(l5, r1, o51);
pl0++;
}
これが、N = 2016 で、218.3[GFLOPS] ぐらい。prefetch 入れなくても何故か良くなった。ブロックサイズは2x6。
Ver8 は THP(transparent hugepage) 有効にすると10%〜20%ぐらい良くなったが、Ver10 は THPの有無が性能に影響を及ぼさなくなっているので、効果あると見てよいはず
| ver | Ver1 | Ver3 | Ver4 | Ver8 | Ver10 |
| GFLOPS | 0.66 | 2.7 | 54.6 | 122.6 | 218.3 |
| 理論性能比[%] | 0.2 | 0.8 | 17.8 | 39.9 | 71.1 |
配列サイズ小さくして 1 thread なら 60GFLOPS になっていて、もう一息で 80% 出そうというところ。
細かいチューン
アンロールしたらスケジューラが頑張りすぎてレジスタスピルしちゃった!
vmovaps %ymm1, %ymm10 vbroadcastss (%rcx,%r8), %ymm1 vfmadd231ps %ymm3, %ymm15, %ymm9 movq -264(%rbp), %rcx # Oh! vfmadd231ps %ymm5, %ymm1, %ymm4 vfmadd231ps %ymm3, %ymm1, %ymm0
そんなときは、レジスタに乗せておきたい値を asm のオペランドにつっこむとよい
https://github.com/tanakamura/matmul-bench/blob/80%25/matmul-bench-fma.c#L320
__asm__ __volatile__(" ":"+r"(n_1),"+r"(n_2),"+r"(n_3),"+r"(n_4),"+r"(n_5));
// Ver11 #APP # 357 "/home/w0/src/matmul-bench/matmul-bench-fma.c" 1 # 0 "" 2 #NO_APP vmovups 256(%rcx), %ymm7 vmovups 288(%rcx), %ymm5 vbroadcastss 16(%rdx), %ymm6 vfmadd231ps %ymm7, %ymm6, %ymm14 vfmadd231ps %ymm5, %ymm6, %ymm3 vbroadcastss 16(%rdx,%r11), %ymm6 vfmadd231ps %ymm7, %ymm6, %ymm13 vfmadd231ps %ymm5, %ymm6, %ymm9 vbroadcastss 16(%rdx,%rax), %ymm6 vfmadd231ps %ymm7, %ymm6, %ymm12 vfmadd231ps %ymm5, %ymm6, %ymm8 vbroadcastss 16(%rdx,%rbx), %ymm6 vfmadd231ps %ymm7, %ymm6, %ymm11 vfmadd231ps %ymm5, %ymm6, %ymm0 vbroadcastss 16(%rdx,%r13), %ymm6 vfmadd231ps %ymm7, %ymm6, %ymm1 vfmadd231ps %ymm5, %ymm6, %ymm10 vbroadcastss 16(%rdx,%r12), %ymm6 vfmadd231ps %ymm7, %ymm6, %ymm4 vfmadd231ps %ymm5, %ymm6, %ymm2
はい完璧。
これで心の中で目標だった 80% を超えた。
| ver | Ver1 | Ver3 | Ver4 | Ver8 | Ver10 | Ver11 |
| GFLOPS | 0.66 | 2.7 | 54.6 | 122.6 | 218.3 | 249.1 |
| 理論性能比[%] | 0.2 | 0.8 | 17.8 | 39.9 | 71.1 | 81.1 |
まとめ
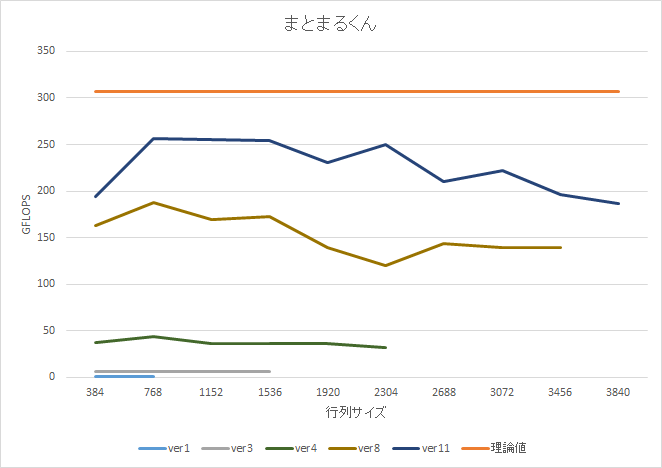
行列サイズが大きくなるほど右肩さがりになってるが、真の dgemm Ninja はサイズ大きいほど性能がサチっていくグラフを描くものだ。dgemm Ninja への道は遠い。
例 : http://tu-dresden.de/die_tu_dresden/zentrale_einrichtungen/zih/forschung/projekte/cell/matmul/ とか
参考
http://www.kata-lab.itc.u-tokyo.ac.jp/OpenLecture/SP20121204.pdf わかりやすい
補足
当日あった質問
perf とかのプロファイラは使ったのか?
一応使ったが役に立った気はしなかった。
キャッシュミス、TLBミスなどは、どの命令のアクセスが問題なのか切り分けられなくて、合計カウントだけ取れてもあまり役に立つ情報ではないという気がした。
どうやってTLBミスの問題に気付いたか?
http://d.hatena.ne.jp/w_o/20141029 この日にCortex-A15向けに真面目にチューンしたのだけど、結局 Cortex-A9 よりも効率良くならなくて、理由が思い付かなかったのだけど、だらだらと
を見てたら、Cortex-A15 の L1 DTLB miss penalty 12cycle, L2 TLB miss penalty 30cycle って結構でかいよな、と気付いて、HaswellもL1 DTLBのパラメータ真面目に見直したら、L1 DTLBの問題の気がした。
Ninja ってなんだよ
http://web.eecs.umich.edu/~msmelyan/papers/isca-2012-paper.pdf
査読付き国際会議で認められたれっきとした用語だから。
Intel や Adobe の人も使ってるぐらい業界でも広く知られた用語だから。
http://www.intel.com/content/www/us/en/research/intel-labs-closing-ninja-gap-paper.html
http://pc.watch.impress.co.jp/docs/news/event/20120613_539834.html
この文章について
この文書はx86/x64最適化勉強会7のために書かれました。