目次
概要
Linuxのパフォーマンス解析ツールであるperfの使いかたの紹介
背景
個人的にperfよくできてると思うので紹介したいというのと、 パフォーマンスカウンタの読み方ってあんまり知られてないみたいなので、 それの解説を書きたい。
構成
perf について説明したあと、パフォーマンスカウンタの読みかた、見かた、を説明する。
perfとは何か
Linuxに付いてくるプロファイラ。 man perf によると、
NAME ---- perf - Performance analysis tools for Linux
と、書いてある。名前がひどいのでなんとかしてほしい。
perf の特徴
個人的には、手軽に使えるのが素晴らしいと思う。
- 2.6.31以降カーネルに標準で付いてる。(Ubuntuだとlinux-tools-common(TODO:あとで確認)で入るはず)
- 特殊な設定が必要無く、コマンドを入れるだけで使える
手元に、何かソースがあったとして、
$ make $ perf record ./a.out $ perf report
これだけで必要な情報は大体手に入る。 (デバッグシンボルぐらい入れたほうがいいが)
例えば、「gcc遅いよ…」とか思ったときは、
$ perf record g++ -c wave.cpp
[ perf record: Woken up 2 times to write data ]
[ perf record: Captured and wrote 0.334 MB perf.data (~14576 samples) ]
w0@n550:~/test/c++$ perf report | head -n 20
# Events: 8K cycles
#
# Overhead Command Shared Object Symbol
# ........ ....... ................. ...................................................
#
2.81% cc1plus cc1plus [.] cpp_get_token
2.63% cc1plus cc1plus [.] ggc_internal_alloc_stat
2.61% cc1plus cc1plus [.] enter_macro_context
2.24% cc1plus libc-2.11.1.so [.] memset
1.96% cc1plus libc-2.11.1.so [.] _int_malloc
1.87% cc1plus cc1plus [.] structural_comptypes
1.81% cc1plus cc1plus [.] push_to_top_level
1.63% cc1plus cc1plus [.] grokdeclarator
1.60% cc1plus cc1plus [.] _cpp_lex_direct
1.31% cc1plus cc1plus [.] ht_lookup_with_hash
1.15% cc1plus cc1plus [.] canonical_type_parameter
0.96% cc1plus libc-2.11.1.so [.] __GI_memcpy
0.95% cc1plus cc1plus [.] decl_assembler_name_equal
0.91% cc1plus cc1plus [.] cp_type_quals
0.90% cc1plus libc-2.11.1.so [.] _int_free
$
cpp_get_token という関数が遅い、というのが一発でわかりますね…
これは、他のプロファイラと比べて、手順が少なくて
- gprof
- 1.makefile 書きかえて、2.make して、実行して、3.gprof
- oprofile
- 1. 管理者権限もらって 2. # opcontrol --init 3. # opcontrol --start 4. 実行 5. # opcontrol --stop 6. opreport
- libprofiler (google-perftoolの)
- 1.LD_PRELOAD設定するか、Makefile書きかえて、2.makeして、3.実行して、4.pprof して 5.functions
- xperf (windowsのプロファイラ)
- 1.シンボルインストールして、2.xperf -on latency して、3.プログラム実行して、4.xperf stop して、5.xperf hoge.etl して、6.マウスポチポチ
- shark (OSXのプロファイラ)
- 1.makeして 2.マウスポチポチして、3.プログラム実行して、4.マウスポチポチ
- VTune (Intelのプロファイラ)
- 1.買ってきて 2.色々インストールして、 3.再起動して、 4.マウスポチポチして、 5.プログラム実行して、 6. マウスポチポチ
- perfmon (http://perfmon2.sf.net/)
- 1.カーネルパッチして…と思いきや、いつのまにかただのperfのフロントエンドになってる。(そして中の人がgoogleの人になっている)
3step でプロファイルできるのは perf だけ!
プロファイラとして必要な機能はひととおり揃っていて、
- コールグラフ
- ソースと対応
- アセンブリと対応
あたりは実装されてる。
あと、機能の半分くらいがカーネルで実装されているので、
- カーネル内のイベント
- ハードウェアパフォーマンスカウンタのイベント
をとることができる。
パフォーマンスカウンタ
最近(…といっても初代Pentiumとかだが…)の高性能CPUは、OoO実行やキャッシュが実装されているので、 命令数、命令サイクル数だけで、パフォーマンスを見積もることが難しい。 そこで、OoO実行や、キャッシュの細かい挙動も含めて、色々計測するために用意されているのが、 「パフォーマンスカウンタ」というものである。
(といっても、「そこまで細かいパラメータ見ないとなんともならないというほど追い詰められることって あんま無いよねー。」とか、思ってしまう人もいるかもしれないけど、それ言うと、この文書の存在理由が半分ほど 無くなってしまうので、どうか、そのあたりは忘れて、子供のような純粋な気持ちで、 続きを読んでいただきたく…!)
このパフォーマンスカウンタを使うと、
- どこで何cycleぐらい時間かかってるか
- どこで何命令ぐらい実行してるか
- どこでキャッシュミスしてるか
- どこで分岐ミスしてるか
- どこで変な命令実行してるか
とか、通常のソフトウェアプロファイラでは取れない値を取ることができる。 x86に限らず、PPCのハイエンドも似たような機能がある。
perf の使いかた
$ perf <command> で、commandを指定すると、そのcommandに対応する処理が行われる。
$ perf help で、使えるコマンド一覧が見れる。
(個人的に)よく使うコマンドは、
- list
- stat
- record
- report
- annotate
あたり。以下、それぞれのコマンドごとについて、使いかたを説明していく
perf list
$ perf list
とすると、perfで取れるイベントの一覧が見られる。
ここで見られる名前が、あとでイベントを指定する時の名前になる。
perf stat
$ perf stat <command>
とかやると、そのコマンドのパフォーマンスカウンタの値が読める。絶対時間見るのもこれ。もうtimeはいらない(userとsys一緒になってるけど…)。
# 多分3.0で表示が変わったので、2.6.xとは若干違ってます
$ perf stat clang++ wave.cpp -c
/x86_64-unknown-linux-gnu
Performance counter stats for 'clang++ wave.cpp -c -I/usr/include/c++/4.5.0 -I /usr/include/c++/4.5.0/x86_64-unknown-linux-gnu':
1365.784289 task-clock # 0.998 CPUs utilized
141 context-switches # 0.000 M/sec
1 CPU-migrations # 0.000 M/sec
65991 page-faults # 0.048 M/sec
4444174007 cycles # 3.254 GHz
2497975253 stalled-cycles-frontend # 56.21% frontend cycles idle
1956298097 stalled-cycles-backend # 44.02% backend cycles idle
4453436807 instructions # 1.00 insns per cycle
# 0.56 stalled cycles per insn
1042873067 branches # 763.571 M/sec
21263258 branch-misses # 2.04% of all branches
1.369163482 seconds time elapsed
$ perf stat g++ wave.cpp -c
Performance counter stats for 'g++ wave.cpp -c':
1266.024145 task-clock # 0.997 CPUs utilized
154 context-switches # 0.000 M/sec
3 CPU-migrations # 0.000 M/sec
51356 page-faults # 0.041 M/sec
4129095611 cycles # 3.261 GHz
2196783424 stalled-cycles-frontend # 53.20% frontend cycles idle
1604101013 stalled-cycles-backend # 38.85% backend cycles idle
4474319375 instructions # 1.08 insns per cycle
# 0.49 stalled cycles per insn
1014333270 branches # 801.196 M/sec
20236994 branch-misses # 2.00% of all branches
1.269729319 seconds time elapsed
# 全くどうでもいいですが、GCCとclangであれだけ実装違うのに、実行時間ほぼ同じになるというのは興味深い現象ですよね…
上から順に、 (CPUによって違うかも)
- task-clock-msecs
- 貰ったCPU時間。右が全体の時間に占める割合(100%=1スレッドなので、マルチスレッドの場合は100%超える)
- context-switches
- した回数
- CPU-migrations
- 別のCPUに移動した回数
- page-faults
- した回数
- cycles
- 使ったCPUのクロック数
- stalled-cycles-frontend
- 結構CPU依存。Atomでは出ない。Sandyでは、デコーダが原因で止まった時間。AMDでは、バックエンドが原因でデコーダが止まってる時間。
- stalled-cycles-backend
- frontendと一緒でCPU依存
- instructions
- リタイアした命令数。右がIPC
- branches
- 分岐した回数
- branch-misses
- 分岐ミスした回数
ボトルネックの雰囲気はつかめると思う。
- IO等、CPU以外の要因で止まってないか? → task-clockちゃんと割り当てられてるか
- CPU性能ちゃんと発揮できてるか? → IPCいくらぐらいか
- スレッドいくつ使ってんのか
perf list で見られる名前を -e で指定すると、そのイベントの回数が取れる。
例えばキャッシュミス率が取りたい場合などは、以下のようにする
$ perf stat -e cache-misses,cache-references g++ -O2 -c wave.cpp
Performance counter stats for 'g++ -O2 -c wave.cpp':
5475028 cache-misses # 10.214 % of all cache refs
53601233 cache-references
1.447147778 seconds time elapsed
あと、-rXXX で、任意のカウンタ値を読める。XXXには、 プロセッサごとのマニュアルを参照して、適切な値を入れる。
x86では、perfのカウンタの指定方法は、上位8bitでumask、下位8bitでnumを指定するようになっている。
例えば、Atomだと、乗算回数をカウントするカウンタは、event num=0x12, umask=0x81 になり(x86マニュアル3-b参照)、 -e r8112 とかやると、perf statで乗算回数をカウントできる。(詳細はあとで)
float a[5000];
float b[5000];
int main()
{
int i;
for (i=0; i<5000; i++) {
a[i] = b[i] * b[i];
}
}
こういうコードをコンパイルして、
$ perf stat -e r8112 ./a.out
Performance counter stats for './a.out':
5000 raw 0x8112
0.000803943 seconds time elapsed
これでカウントできる
他に、カーネル内部で発生するイベントにtracepointが設定してあれば、これも取れて、
$ perf stat -e r8112,kmem:kmalloc ./a.out
Performance counter stats for './a.out':
5000 raw 0x8112
1 kmem:kmalloc
0.000842356 seconds time elapsed
こんな感じ
perf record + perf report
statはそのまま結果を出すだけだが、結果をファイルに収集とかしたいときに使うのが、perf record。
# perf record -a などとすると、システム全体のイベントがとれる(root権限が必要)
stat と同じく、-e でイベントを指定できる。指定方法も一緒。
出力はperf.dataに出る。-o で指定できる。 すでにある場合は、-A(追加)か-f(消して新規作成)かを指定する。
イベント一定回数発生すると、その時のプログラムカウンタをサンプリングするようになっている。サンプリング周期は-cで指定できる。
収集結果は $ perf report を使って見れる。
[~] # perf record -a -e cycles sleep 10
[ perf record: Woken up 9 times to write data ]
[ perf record: Captured and wrote 2.434 MB perf.data (~106339 samples) ]
[~] # perf report | head -n 20
# Events: 35K cycles
#
# Overhead Command Shared Object Symbol
#
3.07% cc1 cc1 [.] ht_lookup_with_hash
2.78% cc1 cc1 [.] _cpp_lex_direct
1.95% cc1 libc-2.13.so [.] _int_malloc
1.62% cc1 cc1 [.] ggc_internal_alloc_stat
1.27% cc1 libc-2.13.so [.] __GI_memset
1.05% cc1 cc1 [.] lex_identifier
0.99% cc1 cc1 [.] grokdeclarator
0.87% cc1 libc-2.13.so [.] _int_free
0.83% cc1 cc1 [.] bitmap_set_bit
0.77% cc1 cc1 [.] htab_find_slot_with_hash
0.74% cc1 cc1 [.] cpp_get_token
0.66% cc1 cc1 [.] c_lex_one_token
0.66% cc1 cc1 [.] c_lex_with_flags
0.65% cc1 cc1 [.] record_reg_classes.constprop.9
0.64% cc1 libc-2.13.so [.] __memcpy_ssse3
perf annotate
perf record の出力結果の詳細を見る。指定したシンボルについて、命令ごとの結果を見れる。 (opannotateみたいなの)
$ cat mul500.c
float a[5000];
float b[5000];
__attribute__((noinline))
void mul500()
{
int i;
for (i=0; i<5000; i++) {
a[i] = b[i] * b[i];
}
}
int main()
{
mul500();
}
$ gcc -O2 mul500.c
$ perf record -f -c 1 -e r8112 ./a.out
[ perf record: Captured and wrote 0.024 MB perf.data (~1035 samples) ]
$ perf annotate mul500
------------------------------------------------
Percent | Source code & Disassembly of a.out
------------------------------------------------
:
:
:
: Disassembly of section .text:
:
: 08048360 <mul500>:
0.00 : 8048360: 55 push %ebp
0.00 : 8048361: 31 c0 xor %eax,%eax
0.00 : 8048363: 89 e5 mov %esp,%ebp
0.00 : 8048365: 8d 76 00 lea 0x0(%esi),%esi
0.00 : 8048368: f3 0f 10 04 85 40 df movss 0x804df40(,%eax,4),%xmm0
0.00 : 804836f: 04 08
1.50 : 8048371: f3 0f 59 c0 mulss %xmm0,%xmm0
0.70 : 8048375: f3 0f 11 04 85 20 91 movss %xmm0,0x8049120(,%eax,4)
0.00 : 804837c: 04 08
97.79 : 804837e: 8d 40 01 lea 0x1(%eax),%eax
0.00 : 8048381: 3d 88 13 00 00 cmp $0x1388,%eax
0.00 : 8048386: 75 e0 jne 8048368
0.00 : 8048388: 5d pop %ebp
0.00 : 8048389: c3 ret
$ perf annotate -l のように、-l付きで実行すると、関数ごとに、どの行で時間かかっているかをソートして見られる。
perf top
topみたいな感じでイベントが発生した回数が見れる。
perf timechart
タイムチャートが見られる。
$ perf timechart record sleep 3 で、記録できて、
$ perf timechart すると、output.svg に結果が出る。

今初めて使ったのでよくわからないけど、なんか面白そうな気がするな…
パフォーマンスカウンタ
パフォーマンスカウンタを読むのにあたって、
- どうやって値を取るか
- 取った値をどう読むか
というのを知っておく必要がある。以下、それぞれについて説明する
パフォーマンスカウンタの値のとりかた
アーキテクチャ依存な部分があって、同じx86でもIntelとAMDでもちょっと違うし、世代ごとにもちょっと違う。 以下、SandyBridgeを例に説明する。まあ、一個理解すれば、他のも大体わかると思う。(Cellも大体一緒だったので、x86以外もそんなに変わらんと思う)
パフォーマンスカウンタのしくみ
ハードウェア的には、大体以下のようになっている
- イベント回数をカウントするカウントレジスタがいくつかある。
- イベント発生源がいくつかある。
- イベントを選択するレジスタがある。(x86ではMSR上にある)
- イベントを選択するレジスタを適切に設定すると、 そのイベントが発生したときに、カウントレジスタの値が増える
- カウントレジスタを適切に設定すると、 イベントが一定回数発生するごとに割り込みが発生する
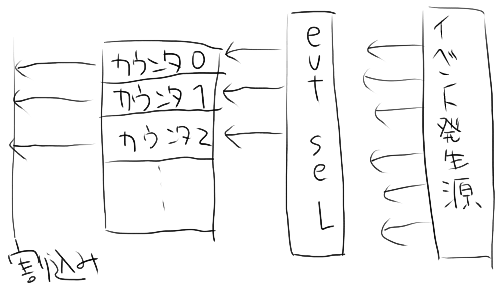
ソフトウェアとしては、以下のような実装になっているのが多いと思う
- 割り込みが発生すると、OSがそのときのプログラムカウンタを記録する
- 記録プログラムカウンタをサンプルとして、サンプルプロファイラを実装する
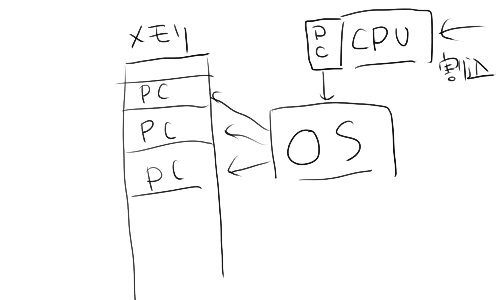
perf も VTune も shark もそれほど設計は変わらないはず。(なので見れる情報もそんなに違いは無いはず)
パフォーマンスカウンタが以上のような実装になっているので、事前に知っておかないといけないことがいくつかある。
- カウントレジスタいくつあるか
- イベント発生源は何があるか
- イベントを選択するにはどうすればよいか
- どうやってサンプリングを開始するか
- どうやってサンプルした値を見るか
以下、SandyBridge + perf の場合について説明する。
SandyBridge のパフォーマンスカウンタ
詳細はマニュアル3Bの30.8
カウンタがコアごとに8ある。HyperThreading有効だとスレッドごとに4個。
イベント発生源は…一杯ありますね…。Appendix A.2 参照。
イベントを選択する方法は、IA32_PERFEVTSELx レジスタを設定するとよい。
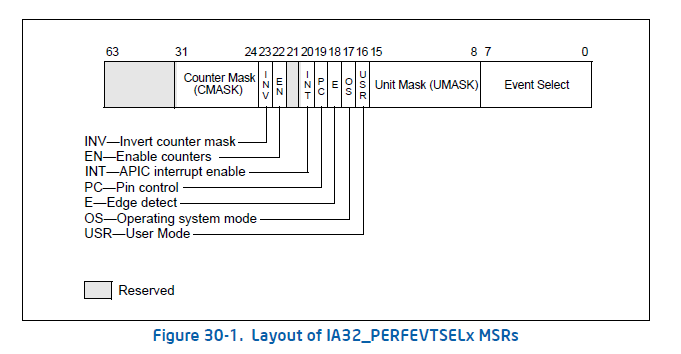
perf でパフォーマンスカウンタを読む
Linuxのperf では、-e r<値> オプションで、IA32_PERFEVTSELx の値を決められる。 設定できるのは、Unit Mask, Event Select, Edge, INV, CMask。 Edgeは、「イベントが発生した回数」が欲しいか、「イベントが原因で止まってる時間」が欲しいか、で決める。(カウンタが対応している必要がある…ように見える) CMaskは、1cycleに複数発生する可能性のあるイベントを計測する時の閾値を設定する。 もしくは、イベントによっては、CMaskの値によって挙動が変わる。
例えば、ストアバッファが一杯で止まってる時間を計測するには、 $ perf stat -e r000008a2 ./a.out とする。

いくつか、よく使う値は名前で指定できる。$ perf list した時に、名前の横に、[Hardware event]と書いてあるものは、 その名前を書けば適切な値が設定される。
$ perf stat すると、カウンタの値が読める。 $ perf record すると、パフォーマンスカウンタ割り込み発生時にサンプルした結果が見られる。
$ perf record -a -e branch-misses sleep 10 $ perf annnotate -l
パフォーマンスカウンタの値の読み方
さて、VTuneだと、「カウンタの値とれるのはいいけどよくわからん」、ということが多い(と聞いたことがある気がする)。 同様にperfだと、「何をとったらいいかよくわからん」ということが多いのではないかと思う(perf使ってる人あまり見たことないからサンプル無いけど…)。 このあたりは、Intel(R) 64 and IA-32 Architectures Optimization Reference Manual に、 ちゃんと書いてあるので、その内容を簡単に説明したい。
IPC
パフォーマンスカウンタを使わないといけないような状況というのは、 「アルゴリズムも適切だし、命令数も十分減らしたが、まだ、なんか謎の原因で速くならない」 というような状況が多いと思う。 なので、まず、「謎の原因で遅い」のか、「そもそも処理数が多すぎて遅い」のか、を切り分けないといけない。 この時、参考になるのが、「IPC (Instructions per cycle)」の値。
(Intelは、これの逆数の「CPI」表記をしてることが多いのだけど、なんか個人的に気持ち悪いのと、 Intel以外は、perfを含めてIPC表記をしてるところが多いように思うので、ここではIPCで表記する。)。
IPCは、$ perf stat すると見られる。
$ perf stat g++ wave.cpp -c
Performance counter stats for 'g++ wave.cpp -c':
1266.024145 task-clock # 0.997 CPUs utilized
154 context-switches # 0.000 M/sec
3 CPU-migrations # 0.000 M/sec
51356 page-faults # 0.041 M/sec
4129095611 cycles # 3.261 GHz
2196783424 stalled-cycles-frontend # 53.20% frontend cycles idle
1604101013 stalled-cycles-backend # 38.85% backend cycles idle
4474319375 instructions # 1.08 insns per cycle <- ここに
# 0.49 stalled cycles per insn
1014333270 branches # 801.196 M/sec
20236994 branch-misses # 2.00% of all branches
1.269729319 seconds time elapsed
パフォーマンスカウンタを使うと、cycle数と、リタイアした命令数がとれるので、その値を使って出している。
Core2 〜 SandyBridgeのCore系のアーキテクチャでは、 整数のピークIPCが3、FPのピークIPCが加算/乗算あわせて2、 整数でも全部の命令がスループット3なわけではないのと、キャッシュミスが入るので、 これらよりも、ちょっと下回るくらい、が、適切なIPCである、と言えると思う。
このIPCが十分高くて、処理が遅い場合は、純粋に命令数が多過ぎなので、 処理を減らすかアルゴリズムを見直す必要がある。
IPCが予想される値よりも低い時は、パフォーマンスカウンタの出番である。 (が、個人的な経験からすると、パフォーマンスカウンタを読んでなんとかなったことは一度も無くて、 Core2以降はややこしすぎて、迷宮入りして終わるケースばっかりですね… なので、以降の情報は、参考程度にとどめておいてください)
アーキテクチャへの理解
さて、何の値からとったらいいのか、というところだが、 ここからはある程度、アーキテクチャへの理解が必要で、 「このアーキテクチャだと、〜が原因で遅くなることがある」 という情報を事前に知っておく必要がある。 作業としては、
- 〜が原因で遅くなってるのではないか、と目星を付ける
- それが本当かどうか、カウンタを見て検証する
- 正解だったら修正する
- 違ってたら別の原因を考える
と、なる。
SandyBridgeでの目星の付けかたについては、 Appendix B.3に書いてあって、
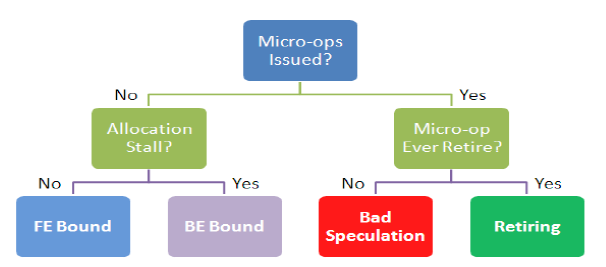
まず、FE/BE/BadSpeculation/Retireのどれなのかを探せ、と。 どういうことかと言うと、(SandyBridgeではなくなってしまうが)Figure B-2.がわかりやすくて、
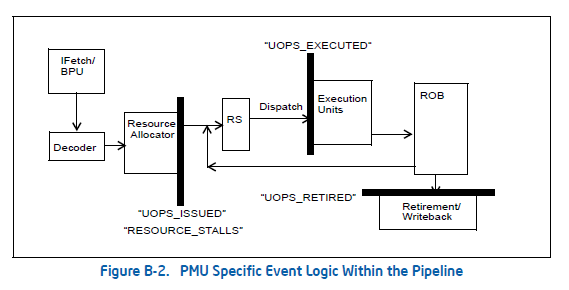
今のOoO実行するCPUは大体こういう構成になっていて、それぞれスループット測って、まず、どこが問題なのか切り分けましょう、という話。
まず、FrontEnd。これは、デコーダがちゃんと動いているかどうか、と、いうのを見る。 SandyBridge以前は、16byte制限とか、LCPストールとか、色々あったけど、 何か解決されちゃった気がするので、あまりここで止まる原因は思い付かないですね… Decoded ICacheはずれると、遅くなるとか、そういう系。
↓ こういうので、
#include <x86intrin.h> #include <stdio.h> char data[64] __attribute__((aligned(128))); #define S_(v) #v #define S(v) S_(v) int main() { int i; int b, e, shift; int nloop = 4096*128; int val = 0, val2 = 0, val3 = 0; #define NUM_INSN 5000 for (i=0; i<nloop; i++) { __asm__ __volatile__(".rept " S(NUM_INSN) " \n\t" "addl $10000, %0\n\t" "addl $10000, %1\n\t" "addl $10000, %2\n\t" ".endr\n\t" :"+r"(val), "+r"(val2), "+r"(val3)); } return val + val2 + val3; }
NUM_INSN が 1000 だと、 IPC=2.83。 NUM_INSN が 3000 だと、IPC=1.02に落ちる。
Frontendで止まってるかどうか、を見るときは、IDQ_UOPS_NOT_DELIVERED を見ろ、と書いてある。
CMaskで、命令のスループットを変えられる。 例えば、Deliverした数が、<= 1の場合は、CMask=1、<= 2 の場合は、CMask=2、とする。 一度に8個までカウントできるので、 $ perf stat -e r0000019c,r0100019c,r0200019c,r0300019c,cycles,instructions ./a.out のようにする。
# NUM_INSN = 3000
$ perf stat -e r0000019c,r0100019c,r0200019c,r0300019c,r0400019c,cycles,instructions ./a.out
Performance counter stats for './a.out':
13842104359 r0000019c
4644045864 r0100019c
3435351767 r0200019c
3006297708 r0300019c
2756409020 r0400019c
4647005816 cycles # 0.000 GHz
4724251832 instructions # 1.02 insns per cycle
1.426943268 seconds time elapsed
# NUM_INSN = 1000
perf stat -e r0000019c,r0100019c,r0200019c,r0300019c,r0400019c,cycles,instructions ./a.out
Performance counter stats for './a.out':
513677324 r0000019c
437757805 r0100019c
74036207 r0200019c
1349694 r0300019c
533618 r0400019c
556779886 cycles # 0.000 GHz
1574771268 instructions # 2.83 insns per cycle
0.176158927 seconds time elapsed
この時、(時々一致してない感があるので理解が怪しいかも…)
# NUM_INSN = 3000
4644045864 r0100019c
^
| この差分が3 deliverしたcycle
v
3435351767 r0200019c
^
| この差分が2 deliverしたcycle
v
3006297708 r0300019c
^
| この差分が1 deliverしたcycle
v
2756409020 r0400019c (完全に止まってる)
# NUM_INSN = 1000
437757805 r0100019c
^
| この差分が3 deliverしたcycle
v
74036207 r0200019c
^
| この差分が2 deliverしたcycle
v
1349694 r0300019c
^
| この差分が1 deliverしたcycle
v
533618 r0400019c (完全に止まってる)
となっていて、NUM_INSNを増やすと、Frontendから後続へ命令が行ってないのがわかる。
次にBad Speculation。 これは、イシューした命令数(UOPS_ISSUED_ANY)と、リタイアした命令数(UOPS_RETIERD.RETIER_SLOT)を比べればよい、と書いてある。
続いて、Backend。ちゃんと命令を実行できているかどうか、というので、スループット出ない原因としては、
- 依存が長い
- 特定のポートに集中してる
というのが多いかと思う。依存が長いものに対しては、RESOURCE_STALLS.RSで、 特定のポートに集中しているかどうかは、ポート毎の命令数が取れるので、それで計測できる。
$ cat dep.c
#include <x86intrin.h>
#include <stdio.h>
char data[64] __attribute__((aligned(128)));
#define S_(v) #v
#define S(v) S_(v)
int a;
int main()
{
int i;
int b, e, shift;
int nloop = 4096*128*8;
int val = 0, val2 = 0, val3 = 0;
#define NUM_INSN 1000
for (i=0; i<nloop; i++) {
#ifdef DEP
__asm__ __volatile__(".rept " S(NUM_INSN) " \n\t"
"addl %0, %0\n\t"
"addl %0, %0\n\t"
"addl %0, %0\n\t"
".endr\n\t"
:"+r"(val),
"+r"(val2),
"+r"(val3));
#else
__asm__ __volatile__(".rept " S(NUM_INSN) " \n\t"
"addl %0, %0\n\t"
"addl %1, %1\n\t"
"addl %2, %2\n\t"
".endr\n\t"
:"+r"(val),
"+r"(val2),
"+r"(val3));
#endif
}
return val + val2 + val3;
}
$ gcc -D DEP dep.c -O3
$ perf stat -e r04a2,cycles,instructions ./a.out
# 04a2 = RESOURCE_STALLS.ANY
Performance counter stats for './a.out':
9436119436 r04a2
12598698436 cycles # 0.000 GHz
12603182632 instructions # 1.00 insns per cycle
3.845161168 seconds time elapsed
$ gcc dep.c -O3
$ perf stat -e r04a2,cycles,instructions ./a.out
Performance counter stats for './a.out':
198563223 r04a2
4222510063 cycles # 0.000 GHz
12595481881 instructions # 2.98 insns per cycle
1.292236557 seconds time elapsed
まとめ
(パフォーマンスカウンタはともかく)perf使いやすいので使いましょう。
履歴
2011/10/01 Ver 2.0 x86勉強会用にアップデート
2009/10/17 Ver 1.0 書いた